

多数据集处理(九): HASH对象的使用哈希娱乐
哈希游戏作为一种新兴的区块链应用,它巧妙地结合了加密技术与娱乐,为玩家提供了全新的体验。万达哈希平台凭借其独特的彩票玩法和创新的哈希算法,公平公正-方便快捷!万达哈希,哈希游戏平台,哈希娱乐,哈希游戏上一篇文章介绍了数据集处理的其他选项和语句。今天,我们将介绍使用HASH对象处理多个数据集。

本系列文章的前面部分已经介绍了运用SET语句和MERGE语句进行数据集之间的拼接,这里将通过实例介绍如何运用HASH对象实现这类操作。相较于SET语句和MERGE语句,使用HASH对象有两个优点,第一点是对数据集的排序没有要求;第二点是,由于HASH对象是放入内存中的数据集,因此在内存允许的情况下,运用HASH对象进行数据集之间的关联时其效率更高。
一般在观测数很多的数据集和观测数较少的数据集进行匹配时,运用HASH对象将较小的数据集加载到内存中,可以非常快速地完成匹配。

这里第一行定义了HASH对象名称,object可以是HASH或HITER,HASH对象名由读者定义。
第二行和第三行分别通过HASH对象名hod的语法定义了HASH对象的KEY变量和DATA变量,这些变量都是DATA步中的变量。


1) 在编译阶段,SAS读入数据集work.Sales中变量及新创建的变量的描述部分,并将其置于PDV中。PDV如下:
2) 在执行阶段,当_N_=1时,定义HASH对象并加载数据到HASH对象中。Call Missing( )语句可以消除日志中部分变量没有初始化的信息。此时,PDV如下:


4) 系统调用product_desc.find( )在Hash对象中检索数据。product_desc.find( )可以指定Sales数据集中的KEY变量,当未指定任何KEY变量的时候,系统默认Sales数据集的KEY变量和HASH对象的KEY变量同名。当系统检索到HASH对象中存在的某个KEY值和PDV中KEY变量的值相等时,则返回代码rc的取值为0,同时将HASH对象中对应的DATA变量的值读入PDV中。此时,PDV如下:
6) 系统读入Sales数据集的第二条观测,并重复第三步到第五步的操作,直到系统读入Sales数据集中的所有观测。
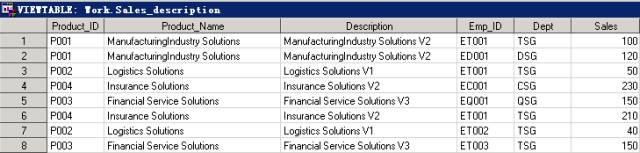
在上述程序中,笔者将没有找到Product_Name和Deion的销售记录输出到了数据集work.exception中,并且创建了一个新变量保存未匹配到的原因。这种方法便于在开发人员调试程序,找到数据中存在的问题。
例4.19:公司现有库存1000台汽车,每台车可以发往全国各个仓库,但是发往每个仓库给公司带来的边际效益不一样,而且每个仓库都有一定的容量限制,现在公司必须决定往每个仓库发多少辆车,同时要使整个公司的效益最高。
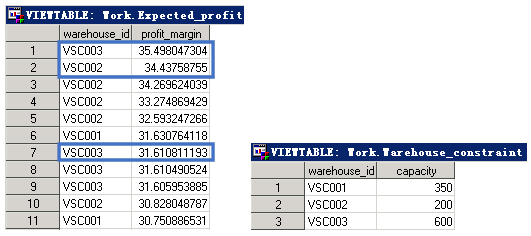
从数据集Work.Expected_profit中可以看出,对于不同的仓库来说,增加一台车带来的效益是不一样的,例如,对于仓库VSC003和VSC002来说,增加第一台车带来的边际效益分别为35.498和34.437;对于同一个仓库,每增加一台车带来的边际效益也是不一样的,例如,对于仓库VSC003来说,增加第一台车时带来的边际效益是35.498,在此基础上增加第二台车时带来的边际效益是31.611,符合边际效益递减规律。
因此在分配的时候,为了实现整个公司的效益最高,分配的原则就是在仓库容量允许的情况下,将每台车都分配给边际效益最高的仓库。以下SAS代码可以实现该目标。

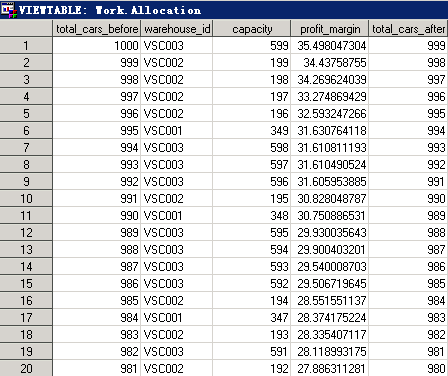
Capacity表示仓库每收到一台车后的剩余容量。例如,在分配前车辆总数为1000台,第一台车分配给VS003,剩余的车辆总数为999台,仓库容量由原来的600降低为599。每分配一台车,系统都调用.REPLACE更新了Hash对象中仓库容量的数据。
Capacity表示仓库每收到一台车后的剩余容量。例如,在分配前车辆总数为1000台,第一台车分配给VS003,剩余的车辆总数为999台,仓库容量由原来的600降低为599。每分配一台车,系统都调用.REPLACE更新了Hash对象中仓库容量的数据。
本系列文章前半部分从PDV的角度,详细介绍了在DATA步中使用SET语句和MERGE语句进行两个及多个数据集纵向串接和横向合并的原理,并比较了使用SET语句和APPEND过程进行数据集纵向串接的异同。在介绍数据集横向合并时,分别介绍了四种不同情形下DATA步的处理原理,这四种不同的情形分别是:不使用BY语句的情形、BY变量值在所有数据集中唯一的情形、BY变量值在某一数据集中存在重复的情形以及BY变量值在多个数据集中存在重复的情形。
后半部分通过示例介绍了用于数据集更新和更改的两个语句:UPDATE语句和MODIFY语句,并补充介绍了数据集处理的一些小技巧。
最后一小节简要介绍了HASH对象的处理原理。运用HASH对象可以简便高效地实现数据集间比较复杂的操作,有兴趣的读者可以参考SAS帮助文档进行更加深入的学习。
【描述性统计】==【SAS统计分析系列:描述性统计分析】系列文章
SAS大学版(SAS® University Edition)是SAS为在校大学生免费提供的基于虚拟机和网页的SAS环境。回复关键字【大学版】,可以查看详细介绍。
如若转载本文,请在文章顶部标注 “本文转自SAS知识 (ID: SASAdvisor),摘自《深入解析SAS — 数据处理、分析优化与商业应用 》”

![]()
《深入解析SAS — 数据处理、分析优化与商业应用》第一作者, SAS软件研究开发(北京)有限公司客户职能部总监。在承担研发工作的同时,夏及其团队负责对SAS非英语市场提供技术支持,并且与在美国及其它地区的团队一起,服务于SAS的SaaS/RaaS业务,同时提供和验证关于SAS产品和技术在应用领域的最佳实践。在加入SAS软件研究开发(北京)有限公司之前,夏就职于SAS中国公司,历任资深咨询顾问、项目经理、首席顾问、咨询经理,拥有丰富的咨询和项目实施经验。在长期的从业经历中,不但为SAS的金融行业客户成功实施了众多深受好评的项目,而且在近年领导实施了非金融行业的多个大数据分析项目。